
O curso “Language technology in the Amazonian/Uralic context: Universal Dependencies, Text Recognition and Audio Corpora” é promovido como parte das atividades do projeto de cooperação interinstitucional internacional “Indigenous Studies on Language, Traditional Knowledge and the Environment within Amazonian-Finish Collaboration“, envolvendo a Grupo de Estudos sobre Línguas e Culturas Indígenas (GELCIA) do Programa Pós-Graduação em Letras da Universidade Federal do Pará (UFPA), a Universidade Federal do Pará (UFAM) e a Universidade de Helsinque, financiado pela Finish National Agency for Education, sob coordenação da Dra. Pirjo Kristiina Virtanen (Univ. de Helsinque, Finlândia), Sidi Facundes (UFPA, Brasil), e Dr. Tiago Mota Cardoso (UFAM, Brasil). Os ministrantes do curso, Dr. Jack Rueter e Dr. Niko T. Partanen, são linguistas da Universidade de Helsinque especializados no desenvolvimento de tecnologias da linguagem, com foco em línguas de grupos minoritários.
Período: 25 a 29 de setembro, 2023 (ver detalhes no cronograma abaixo).
Local: Sala 14, Prédio de Pós-Graduação em Letras, Univ. Federal do Pará, Campus Universitário do Guamá
Link para solicitação de inscrição: (Inscrições encerradas)
O curso foi planejado para ser apenas presencial, contudo, a pedidos, o seguinte link foi criado para uma tentativa de transmissão online, porém, sem garantia de atendimento adequado por esse meio: https://meet.google.com/bpe-kdjp-cxz
Outras informações: gelcia@ufpa.br, WhatsApp: 91 99122-8890
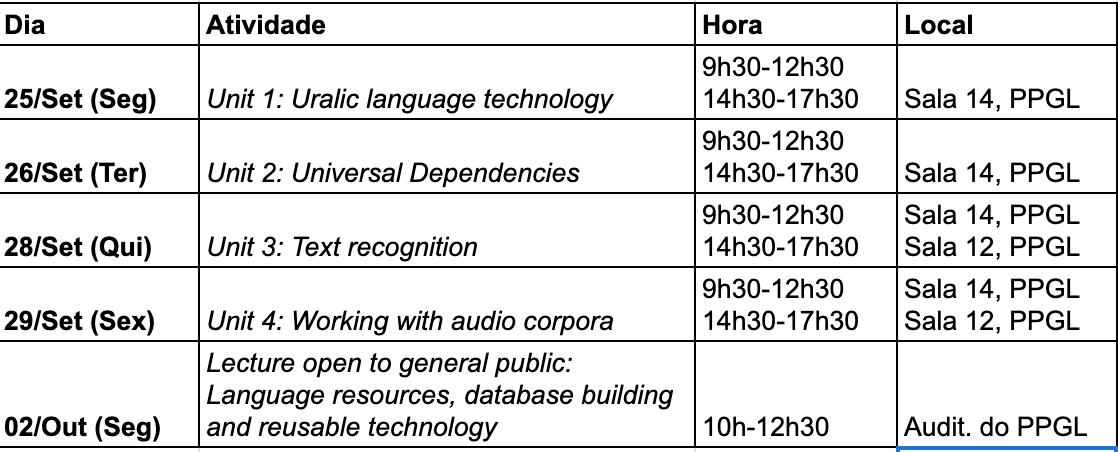
Cronograma de Atividades
Conteúdo do curso
O curso está organizado para conter aproximadamente seis unidades de ensino. A primeira é para nos conhecermos e com o que estamos trabalhando, e a última é encerrar a experiência até agora.
Introdução
Discutimos nossa experiência, os idiomas que trabalhamos e os projetos em que estamos envolvidos. Também mostramos exemplos das áreas de tecnologia linguística em que trabalhamos anteriormente. Esperamos que os alunos aprendam o que eles têm feito antes e com que línguas, e que tipo de desejos e necessidades eles teriam para os seus próprios dados de investigação.
Existem diferentes tipos de dados de pesquisa que podem ser relevantes para o curso. Primeiro, todos os materiais de texto em qualquer idioma podem ser trabalhados. Então o áudio e as transcrições relacionadas são muito úteis e próximos daquilo com que trabalhamos há anos. Um dos focos do curso será como tratar e organizar esses tipos de dados para que possam ser usados efetivamente como um corpus e possam ser integrados em aplicações e ferramentas que utilizam tecnologia de linguagem. Isto é importante do ponto de vista da reutilização de dados em geral, e também para que possamos analisar os nossos materiais da forma mais eficaz e fácil possível.
Abordamos este tema a partir de uma direção onde diferentes recursos de linguagem digital estão disponíveis. Podem ser textos já digitais ou qualquer tipo de material impresso ou manuscrito, e também o áudio bruto, combinado com qualquer tipo de transcrição, é muito relevante aqui. Discutiremos ambos os métodos que podemos usar para recuperar o texto em formato eletrônico a partir de diferentes fontes analógicas, mas ao mesmo tempo muitas abordagens da tecnologia da linguagem são indiferentes à origem do texto. Tentamos mostrar como esses diferentes tópicos estão intimamente interligados.
Unidade 1: Tecnologia da linguagem Urálica
Nesta seção abordamos a tecnologia linguística atualmente disponível para as línguas urálicas, com foco particular na morfologia regular. Passamos por exemplos das línguas urálicas, onde analisadores baseados em regras têm sido amplamente utilizados tanto em pesquisas quanto em diversas aplicações. Estes são analisadores robustos que acreditamos que podem ser úteis também no contexto de documentação de linguagem. Quando estamos descrevendo uma nova linguagem, pode ser muito eficaz incluir os lexemas e a morfologia conhecidos em uma estrutura como esta, pois podemos usá-la também para gerar possíveis novas formas e testar com textos existentes até que ponto nossa análise segue o que realmente acontece. na língua.
Unidade 2: Dependências Universais
Usamos amplamente o projeto Dependências Universais para publicar partes anotadas de nossos corpora. Curiosamente, o projeto já inclui hoje línguas tanto da família das línguas urálicas quanto da região amazônica.
O projeto Dependências Universais contém bancos de árvores anotados, que são sentenças analisadas morfológica e sintaticamente. Também é possível incluir outras informações como traduções e glosas. O que torna as Dependências Universais tão úteis em nosso contexto é que com elas podemos tentar comparar diferentes idiomas, já que a convenção de anotação visa a consistência entre diferentes famílias de idiomas. O esquema de anotação também é complexo o suficiente para pensarmos que pode expressar suficientemente as diferenças de idiomas individuais.
Disto segue-se que o esquema de anotação leva algum tempo para ser compreendido. Nesta seção do curso, tentamos apresentar as Dependências Universais de maneira suave e agradável, usando exemplos familiares aos participantes do curso.
Como ambos os instrutores do curso trabalharam em estreita colaboração com o projeto Dependências Universais, também incentivamos os alunos a contribuir com o projeto, se quiserem, e trazer seu próprio conjunto de frases para o curso é mais que bem-vindo. Nesta unidade, a sessão de ensino prático poderia continuar como uma sessão de anotação partilhada mais informal, onde trabalhamos e tentamos anotar frases em conjunto.
Unidade 3: Reconhecimento de texto
Utilizamos as notas de campo manuscritas de Apurina como exemplo na parte em que detalhamos como esse tipo de material pode ser pesquisável e transformado em texto eletrônico por meio do software Transkribus.
A unidade consiste em algumas partes distintas, à medida que discutimos as questões de layout e reconhecimento de texto, como treinar novos modelos para a ferramenta e como recuperar o texto e pesquisar algo nele.
Unidade 4: Trabalhando com corpora de áudio
Nesta seção, examinamos várias maneiras de organizar um corpus de linguagem falada de forma que resulte em um conjunto de dados legível por máquina. Combinamos isso com diferentes formas de monitorar automaticamente a qualidade do corpus resultante. Isto também se conecta ao trabalho discutido anteriormente, pois este tipo de material pode ser conectado ao trabalho sobre tecnologia da linguagem e também à criação de treebank.
Analisaremos algumas abordagens para automatizar essas tarefas, que incluem ferramentas de segmentação automática, principalmente com o pacote pyannote Python, e alinhamento automático de uma transcrição e áudio existentes (se os alunos estiverem interessados). Além disso, discutimos a situação atual do reconhecimento automático de fala no contexto de documentação de linguagem, e demonstramos como um fluxo de trabalho como esse também funciona.
Resumo
Aqui resumimos o que fizemos e quais foram os pontos mais importantes para focar mais profundamente.
![]()
![]()

![]()

![]()
Puxa, eu adoraria ter participado. Mas quando recebi a informação o evento já estava ocorrendo e nos dias subsequentes eu já tinha bancas inadiáveis!